

이벤트 참여용으로 작성된 게시물이며, 부정행위 방지를 위해 대회 종료 이후 일부 수정되었습니다.
Tactic 유출 방지를 위해, 세부적인 익명처리 기술은 발표 평가 이후 별도 포스팅 예정입니다.
대회 소개(기술 부문)
본 대회는 개인정보보호위원회(활용부문)와 과학기술정보통신부(기술부문)가 주최하고, KISA에서 주관하는 공식 경진대회이다.
대회는 기술 부문과 활용 부문으로 구분된다.
- 활용부문: 가명정보를 활용(분석, 결합 등)하여 추진한 우수사례(모델, 연구, 사업, 통계 등) 제작
- 기술부문: 특정분야의 데이터셋을 시나리오에 따른 적절한 가명 처리 기술을 적용
기술 부문은 센스와 정교함이 매우 중요하다고 느꼈다.
본인은 기술 부문에 참가했기에, 이 글에서는 기술 부문에 한정하여 후기를 정리한다.

대회 일정
대회는 예선 -> 본선(기술평가 -> 발표평가) -> 결과 발표 -> 시상식 순으로 진행된다.
전체적으로 준비 기간이 긴 만큼, 철저한 사전 준비를 해두면 좋다.
참가자는 제공된 특정 분야의 데이터셋을 바탕으로 시나리오에 맞는 가명처리 및 익명처리 기술을 적용해야 한다.
예선 하루 전, 비밀번호가 설정된 데이터셋과 보고서 양식이 배포되며, 예선 시작 30분 전에는 팀원 신분 확인과 안내사항이 전달된다.
처음 참여하는 입장에서는 어떤 절차를 따라야 할지 몰라 혼란스러우니, 대회 사전 설명회를 필수 참석할 것을 권장한다.
예선 후기
예선에서는 정형 데이터, 본선에서는 비정형 데이터가 제공된다.
우리는 본선 진출보다 경험을 목적으로 참여했기에, 기대보다 긴장감이 컸다.
팀원은 모두 같은 학과 사람들로 구성했으며, 역할 분배는 다음과 같다.
팀원A: 개인정보보호 기술 및 동향 분석
팀원B: 적용 tactic 선정
팀원C: tactic 분석 및 검증
본인: 데이셋 가명 처리 및 통계 분석
가명처리 작업에 많은 시간이 소요되어 보고서 작성은 팀원 A, B, C가 주도했으며, 결과적으로 팀원 전원이 효율적으로 기여했다.
초기에는 데이터셋을 보아도 방향을 잡지 못해 혼란스러웠지만, 곧 핵심을 이해하고 각자 역할을 정해 몰두할 수 있었다.
결국 이 대회는 개인정보 보호와 가명처리 기술이 중심이다.
부족한 지식은 빠르게 보완하면 된다. 우리 팀원은 디스코드를 통해 약 2시간동안 자율 학습을 진행했다.
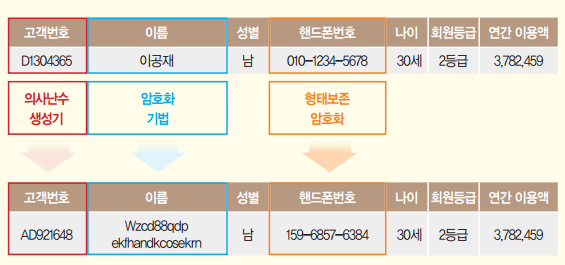
핵심 개념
데이터셋을 이해하기 위해 다음 4가지를 중심으로 접근하면 효율적이다.
직접 식별자(Direct Identifier), 준식별자(Quasi-Identifier), 민감 정보(Sensitive Information), 비민감 정보(Non-Sensitive Information)
본 대회 데이터셋은 이러한 정보들이 혼합된 형태였으며, 데이터 왜곡없이 적절히 처리하는 것이 핵심이다.
PIPC에서 이미 제공되는 자료 중 핵심을 훑을 필요가 있었다.
프라이버시 보호 모델 적용
다양한 프라이버시 보호 모델을 실습해봤다.
여기에는 k-Anonymity, l-Diversity, t-Closeness 등의 모델이 존재하며 시행착오를 겪어가며 모델의 특성과 한계를 알아갔다.
일부 적용해본거 below:
참여 사진(대회 이벤트용)
화합 잘되는 사이버보안학과 화석 모임.
모두가 가명처리 경험이 처음이었지만, 실제로 작업해보니 생각보다 많은 것을 배우고, 대회가 즐겁다고 입을 모았다.
Tips
1. 가명-익명처리 가이드라인 기준으로 지표를 기반으로 채점이 이루어진다. 사전설명회에서 공유된 레퍼런스를 꼼꼼히 참고하자.
2. 기술 경험이 많지 않아도 쉽게 접근할 수 있다. 센스와 세밀함이 중요한 영역이므로 데이터 처리에 관심이 있다면 누구든지 도전해보면 좋겠다.
Ref
당시 활용 및 향후 학습용으로 구해놓은 것들
- Anonymisation Techs
- ISO/IEC: Privacy-Enchancing data de-identification techniques
- ISO/IEC: Privacy-Enchancing data de-identification techniques
- NIST: De-Identification of Personal Information
- k-Anonymity
- l-Diversity
- t-Closeness
- CRAN manual
- IBM diffprivlib
- Google differential-privacy
'후기' 카테고리의 다른 글
| [후기] KISA 2025 블록체인 누리단 발대식 (3) | 2025.07.26 |
|---|---|
| [고려대] 군전역예정자로 복학하는 방법 (0) | 2024.06.13 |
| KISA 실전형 사이버훈련장 일방향 침해사고 고급과정 후기 (0) | 2024.05.20 |
| 공군 정보보호병 합격 스펙 리뷰 (2) | 2024.05.20 |