


Heap이 왜 어려울까?
1. Stack Memory와 너무 다른 구조
Stack 메모리에서는 단순히 push, pop 동작만 하기에 우리가 이해하는데 큰 어려움은 있지 않았다.
반면 Heap의 메모리 할당은 비정형적이고 동적이기에 정적으로 할당되는 Stack 메모리보다 배우기 까다롭다.
2. 너무 많은 Memory Allocators
Google의 tcmalloc
GNU의 ptmalloc2
FreeBSD/Firefox의 Jemalloc
Solaris의 Libumem
등 동적 메모리 할당자는 종류가 많다.
운영체제, 메모리 재사용, 단편화, 낭비등 여러면에서 각각 구현 목표가 다를 수 있다.
ptmalloc2.. 빠르고 쉽게 알아보자
우선 리눅스 glibc에서는 ptmalloc(pthreads malloc)을 제공한다.
dlmalloc에서 쓰레드 기능이 추가되었으며 기본 알고리즘은 모두 dlmalloc을 따른다.
https://www.gnu.org/software/libc/manual/html_node/The-GNU-Allocator.html
Heap 영역 직접 찾아보기
우선 바이너리에서 heap 영역은 malloc이나 calloc와 같이 할당이 된 후에 할당된다.

vmmap으로 봤을 땐 heap 영역은 0x404000 ~ 0x425000이다. 그러면 그 주소를 까면 값을 읽을 수 있겠다?
아쉽게도 0x404000부터 잡으면 우리가 데이터를 넣었다해도 볼 수 없다.
그 이유는 tcache_perthread_struct 때문이다.
복잡하긴 하지만 tcache_init에서 먼저 해당 구조체를 넣어주기 때문인데, x86-64 시스템 기준으로 0x280 데이터만큼 할당한다.
typedef struct tcache_perthread_struct
{
uint16_t counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;해당 구조체는 64 * 2 + 64 * 8 = 640 = 0x280 크기를 갖고 있으며 청크의 헤더 (0x10)을 더하면 0x290의 크기를 갖고 있다.
즉, ptmalloc에서는 heap을 처음 할당하면 heap이 할당된 위치에서 0x290 (대체로) 떨어진 위치에 있다.
청크의 구조 및 순서
우선 heap 데이터는 chunk로 관리가 된다.
레퍼런스가 있어야 공부하기 쉬우니 정말 간단하게 보자
malloc으로 할당된 데이터와 이를 관리하기 위한 16바이트의 헤더를 chunk라고 부른다.
즉 chunk의 크기는 내가 할당한 크기 + 0x10(16) 이라는 소리이다
그냥 별 거 없는 useless한 코드이다. 0x60만큼 heap에 allocate하는 내용인데 직접 분석을 해보면 0x4042a0부터 우리가 넣은 데이터가 들어갔다. 하지만 그 위 0x404298엔 0x71이 들어가있는데 이는 ptmalloc이 allocated된 chunk를 관리하기 위한 방법이다.
0x404290부터 16바이트는 해당 청크의 헤더이다.
0x4042a0부터 0x4042ff까지는 해당 청크의 데이터 영역이다.
0x404290부터 매핑되는 이유는 방금 설명했으니 다시 명심하길 바란다.
여기까지 이해했으면 heap 구조를 30% 이해했다고 볼 수 있다!! 오예
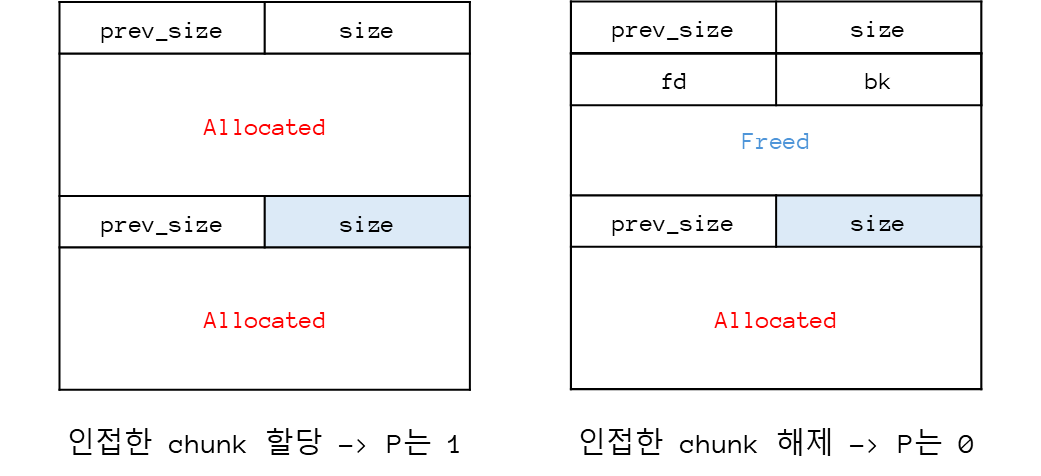
1. Allocated chunk (할당된 청크)
방금 소개한 코드를 표로 정리하면 이렇게 된다. Heap은 낮은 주소에서 높은 주소로 간다! 잘 기억하자.
prev_size
여기서 주소 0x404290부터의 8바이트는 prev_size이다.
prev_size는 바로 앞쪽(낮은 주소)에 있는 청크의 크기이다.
2개의 청크가 나란히 할당되어있는 경우 0으로 초기화된다.
앞쪽 chunk가 free될 땐 앞 size가 현재의 prev_size에 초기화되게 된다.
size
주소 0x404298부터 8바이트는 size이다.
size에서는 chunk의 크기와 3가지의 속성을 나타낸다.
청크는 8바이트(32bit) 또는 16바이트(64bit) 단위로 정렬되기에 하위 3bits가 사용되지 않는다.
따라서 이 하위 3개의 비트를 A M P로 각각 나뉘어 flag로 사용한다.
P가 중요한데 fastbin일 때 설정되기도 한다.
이게 더 가시성이 좋을 거 같다고 판단했다.
별 거 없다!
2. Freed chunk (해제된 청크)
Memory Allocator가 효율적으로 관리하기 위해서 비슷한 크기끼리 관리하면, Linked List를 사용한다.
fd(foward), bk(backward)로 Linked List 포인터로 생각하면 된다.
크기가 큰 경우 fd next_size, bk next_size 로 관리하게 된다.
fd (Forward Pointer) : 해제된 다음 청크를 가리키는 포인터
bk (Backward Pointer) : 이전 해제된 청크를 가르키는 포인터
- Free List Insertion:
- 해제된 청크를 크기에 따라 free linked list에 삽입 -> fd와 bk 포인터 업데이트
- Free List Removal:
- 새로운 할당 요청 시 적절한 청크를 찾아 free linked list 제거 -> 인접 청크의 fd와 bk 포인터 업데이트
- Merge:
- 인접한 해제된 청크들을 병합하여 더 큰 청크로 만듦
- 단편화를 줄이고 더 큰 연속 메모리 블록 관리
3. Top Chunk

별 거 없다. Heap 영역에서 tcache 구조체를 포함해 할당되지 않았다는 가정아래 0x21000 의 크기를 갖는다.
특징으로 힙 영역 가장 마지막 위치 (Heap 중에서 제일 높은 주소)에 있다.
동적할당시 ->
1. 재사용 가능한 청크가 있으면 -> 0x40 데이터를 할당할건데 top chunk를 쪼개지 않아도 중간에 빈 부분에 할당할 수 있는가 : Top Chunk에서 쪼개지 않는다.
2. 재사용 가능한 청크가 없으면 -> Top Chunk를 쪼개서 할당한다.
Top chunk의 크기보다 큰 영역은 할당이 불가능하다.
'Computer Security > System Hacking' 카테고리의 다른 글
| glibc version에 따른 mitigations & heap exploitation (0) | 2024.07.07 |
|---|---|
| [ptmalloc] 리눅스 동적할당 heap 하게 공부하자 (2) : Boundary Tag, Binning편 (0) | 2024.07.03 |
| [Sandbox] 샌드박스 보안 이해하기 : 보호 기법과 우회 방법 + Linux (0) | 2024.06.30 |
| [Privilege Escalation] pwnable 관점에서 chroot jail 탈옥하기 (0) | 2024.06.29 |
| 재밌게 하는 시스템해킹 학습 방법 (0) | 2024.06.25 |